紫东太初
01
简介
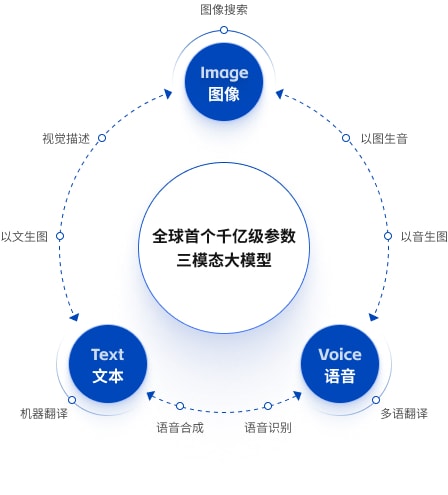
“紫东太初”是全球首个千亿参数三模态大模型,由武汉人工智能研究院、中科院自动化所与华为联合研发,开拓性地实现了图像、文本、语音三个模态数据之间的“统一表示”与“相互生成”,理解和生成能力更接近人类,向通用人工智能迈出了重要一步。
02
核心原理
“紫东太初”首次实现了三模态间相互转换和生成,其核心原理是视觉、文本、语音不同模态通过各自编码器映射到统一语义空间,然后通过多头自注意力机制学习模态之间的语义关联以及特征对齐,形成多模态统一知识表示,再利用编码后的多模态特征,然后通过多头自注意力机制进行通过解码器分别生成文本、图像和语音。
03
关键技术与核心能力
“紫东太初”多模态大模型拥有三大关键技术和六大核心能力。
三大关键技术

多模态理解与生成多
任务统一建模

面向国产化软硬件的
高效训练与部署

多模态预训练模型架构
设计与优化
六大核心能力
多模态统一表示
与语义关联

预训练模型
网络架构合计

模型适配
与分布式训练

跨模态内容转化
与生成

标注受限自监督
模型学习

模型轻量化
与推理加速
典型应用
多模态人工智能,走向千行百业
智能制造
智慧文旅
智能驾驶
媒体创作
手语教学
魏桥纺织:
在纺织制造领域,与魏桥集团合作了布匹缺陷检测设备,该设备通过接入“紫东太初”大模型的质检摄像头识别70多种布匹瑕疵,能够在较短时间内就满足生产的精度要求,在验布检验环节相比人工实现了质的突破,瑕疵识别检出率高达95%。还能够基于声音发现瑕疵,提升纺织行业织布、验布效率,助力纺织工业质检。
 公众号
公众号 Copyright © 武汉人工智能研究院(WAIR)  鄂公网安备42018502006594号
鄂公网安备42018502006594号